آپاچی اسپارک یک فریمورک قدرتمند و متنباز برای پردازش دادههای بزرگ است که بهدلیل سرعت و کارایی بالایی که دارد، به یکی از ابزارهای اصلی و پرکاربرد در دنیای دادهکاوی تبدیل شدهاست. این فریمورک با ارائه قابلیتهای متنوعی مانند پردازش موازی، یادگیری ماشین و تحلیل دادههای بلادرنگ، به کاربران این اجازه میدهد که دادههای خود را به سادگی و با کارایی بالا، مدیریت و تحلیل کنند.
بهدلیل محبوبیت روزافزون آپاچی اسپارک، میخواهیم در این راهنما به بررسی ویژگیها، مزایا و مراحل نصب این فریمورک جذاب بپردازیم تا به شما در استفاده بهینه از آن کمک کنیم. با ویپیاس مارکت همراه باشید…
تعریف آپاچی اسپارک
اسپارک در سال ۲۰۰۹ در آزمایشگاه AMPLab دانشگاه کالیفرنیا، برکلی توسعه یافت. در حال حاضر، این فریمورک توسط بنیاد نرمافزار آپاچی نگهداری میشود و یکی از بزرگترین جامعههای متنباز در حوزه دادههای کلان را با بیش از ۱۰۰۰ مشارکتکننده دارد.
تا اینجا فهمیدیم که آپاچی اسپارک یک موتور پردازش داده سریع و متنباز برای برنامههای یادگیری ماشین و هوش مصنوعی است که توسط بزرگترین جامعه متنباز در حوزه دادههای کلان پشتیبانی میشود. اما دلایل اهمیت آپاچی اسپارک چیست و چرا باید با آن آشنا باشیم؟
آپاچی اسپارک (که معمولا به آن فقط اسپارک میگویند) میتواند بهراحتی مجموعههای داده بزرگ را مدیریت کند. این ابزار، یک سیستم خوشهای سریع و چندمنظوره است که برای PySpark (یک API پایتون برای آپاچی اسپارک است که به کاربران این امکان را میدهد تا از قدرت پردازش دادههای بزرگ اسپارک با استفاده از زبان برنامهنویسی پایتون استفاده کنند) مناسب است. این فریمورک بهگونهای طراحی شدهاست که سرعت محاسباتی، مقیاسپذیری و قابلیت برنامهنویسی موردنیاز برای دادههای کلان را برای دادههای استریم، دادههای گرافی، تحلیلها، یادگیری ماشین، پردازش دادههای بزرگ و برنامههای هوش مصنوعی فراهم کند.
موتور تجزیهوتحلیل اسپارک، دادهها را ۱۰ تا ۱۰۰ برابر سریعتر از ابزارهای دیگر، مانند هادوپ پردازش میکند. این فریمورک با توزیع استریمهای پردازش در خوشههای بزرگ کامپیوتری، مقیاسپذیری را با داشتن قابلیتهای موازیسازی و تحمل خطا، فراهم میکند. همچنین شامل طیف گستردهای از API برای کار با زبانهای برنامهنویسی که در میان تحلیلگران داده و دانشمندان داده محبوب هستند مانند اسکالا، جاوا، پایتون و R است.
اگر برای پردازش دادههای خود با زبان برنامهنویسی پایتون سروکار دارید، پیشنهاد میکنیم برای داشتن بالاترین حد سرعت و بهرهوری از سرور مجازی پایتون که برای کار در محیطهای توسعه طراحی شدهاست، استفاده کنید.
ویژگیهای فریمورک اسپارک

میتوانید به آپاچی اسپارک به چشم یک ابزار چندکاره پردازش Big Data نگاه کنید. این فریمورک سریع، چندمنظوره، قابل تطبیق و بهراحتی در دسترس است و هر کسی که در دنیای دادههای کلان فعالیت میکند، میتواند بهراحتی از آن استفاده کند.
از مهمترین ویژگیهای آپاچی اسپارک میتوان به موارد زیر اشاره کرد:
1. پردازش در حافظه (In-memory processing):
اسپارک سرعت پردازش فوقالعاده درخشانی دارد. این ابزار با استفاده از پردازش دادههای در حافظه (in-memory data processing) با RDD، توانسته از پیشینیان خود مانند MapReduce بهتر عمل کند. در واقع شما با استفاده از اسپارک، به جای اینکه منتظر خواندن از دیسک باشید، دادهها را بهصورت بلادرنگ (real time) پردازش میکنید!
اگر بهدنبال یک سرور هستید و مواردی مانند سرعت پردازش بالا، ایمنی و پهنای باند برایتان مهم است، بهتر است گزینههایی مانند سرور اختصاصی که از بهترین تجهیزات سختافزاری برای سرورهای خود استفاده میکنند، انتخاب کنید.
2. چندمنظوره بودن (Versatile):
اسپارک بیگ دیتا یک ابزار تککاربردی نیست. این فریمورک بهراحتی بارهای کاری متنوعی را از پردازش دستهای مجموعههای داده بزرگ گرفته تا استریمهای داده بلادرنگ و پرسشهای تعاملی مدیریت میکند. شما میتوانید آن را بهعنوان یک ابزار چندکاره برای نیازهای دادههای کلان خود درنظر بگیرید.
3. قابلیت استفاده مجدد (Reusability):
یکی از ویژگیهای معماری اسپارک این است که شما را به استفاده مجدد از کد در وظایف پردازش مختلف تشویق میکند و به این ترتیب، کارایی و ثبات را ارتقا میدهد. این مانند داشتن یک دستور پخت نان چندمنظوره است که میتوان آن را برای تهیه غذاهای مختلف تطبیق داده و در زمان و تلاش صرفهجویی کرد.
4. تحمل خطا (Fault tolerance):
ویژگیهای تحمل خطای اسپارک مانند RDD lineage، اجرای مجدد وظایف و نقاط چک تضمین میکنند که خطوط گذرگاه داده شما حتی درصورت بروز خطا نیز فعال باشند. بدینصورت، میتوانید از قابلیتهایی مانند پشتیبانگیریهای خودکار، تلاشهای مجدد و شبکههای ایمنی برای پردازش دادههای کلانتان بهره ببرید.
5. پردازش بلادرنگ (Real-time processing):
ویژگی اسپارک استریمینگ (Spark Streaming) امکان پردازش مداوم دادهها با تاخیر کم را فراهم کرده و استریمهای داده را در زمان نزدیک به بلادرنگ مدیریت میکند. این ویژگی برای بینشها (insights) و اقدامات سریع بسیار ایدهآل است.
همچنین، آپاچی اسپارک بهعنوان یک فریمورک پردازش دادههای توزیعشده، میتواند بهعنوان یک بکاند برای وب سرورها عمل کرده و دادهها را از منابع مختلف پردازش کند. بهعنوان مثال، وب سرورها میتوانند درخواستهایی برای پردازش دادهها به اسپارک ارسال کنند و نتایج را به کاربران نهایی ارائه دهند. این ارتباط به وب سرورها این امکان را میدهد تا از قدرت پردازش سریع اسپارک بهرهبرداری کرده و دادههای بزرگ را بهصورت بلادرنگ تحلیل کنند.
6. ارزیابی تنبل (Lazy evaluation):
اسپارک اجرای خود را تا زمان نیاز به تاخیر میاندازد و با اجتناب از محاسبات اضافی، عملکرد را بهینه میکند. این ویژگی مانند این است که یک سرآشپز باهوش، آشپزی خود را فقط زمانی که سفارش میرسد شروع میکند تا در زمان و انرژی صرفهجویی کند.
7. Spark GraphX:
این یک کتابخانه پردازش گراف داخلی برای کاوش روابط و الگوها در دادههای متصل است. شما میتوانید از این جعبهابزار مفید برای کشف شبکهها و ارتباطات پنهان استفاده کنید.
8. یکپارچگی با هادوپ:
اسپارک بهطور یکپارچه با ذخیرهسازی توزیعشده هادوپ (HDFS) و مدیریت منابع (YARN) آن کار میکند تا امکان دسترسی و پردازش دادههای بزرگ را فراهم کند.
9. سهولت استفاده و دسترسی:
یکی از ویژگیهای برجسته اسپارک، رابط کاربری دوستانه آن است. چه یک مهندس داده با تجربه باشید و چه تازهوارد در فناوریهای دادههای کلان، میتوانید از تعداد بی شماری از API ساده و مستندات غنی اسپارک با هر سطح مهارتی که هستید استفاده کنید.
10. MLlib برای یادگیری ماشین:
MLlib اسپارک (کتابخانه یادگیری ماشین)، کار پیادهسازی الگوریتمهای یادگیری ماشین را ساده میکند. این کتابخانه با مجموعهای بزرگ و جامع از ابزارها برای خوشهبندی، طبقهبندی، رگرسیون، فیلترکردن مشارکتی و بسیاری از ابزارهای دیگر، به دانشمندان داده این امکان را میدهد که مدلهای قوی را بهراحتی بسازند و پیادهسازی کنند.
11. جامعه و اکوسیستم:
آپاچی اسپارک دارای یک جامعه پرجنبوجوش و بزرگ است. در این جامعه، مواردی مانند دریافت پشتیبانی، پیداکردن منابع و دسترسی به طیف وسیعی از ادغامها و گسترشهای شخص ثالث با کمک یک پایگاه کاربری متنوع و فعال نسبتا راحت و بیدردسر است میشود. اکوسیستم اسپارک با اتصالات به پایگاههای داده مختلف و ادغام با خدمات ابری، همواره در حال تکامل خود است.
12. بهینهسازی کوئری تطبیقی (AQO):
ویژگی Adaptive Query Optimization که در اسپارک ۳.۰ معرفی شده، برنامههای اجرایی کوئری را بهطور پویا بهینه میکند و با تطبیق با آمار دادههای در حال تغییر و الگوهای بار کاری، عملکرد را بهبود میبخشد. این ویژگی، کارایی اسپارک را در پردازش کوئریهای پیچیده و مجموعههای داده بزرگ افزایش میدهد.
13. پردازش داده یکپارچه:
توانایی اسپارک در مدیریت پردازش دستهای، استریمهای بلادرنگ، کوئریهای تعاملی و پردازش تکراری تحت یک چارچوب یکپارچه، معماری کلی خطوط گذرگاه داده را ساده میکند. این رویکرد یکپارچه، بار مدیریت سیستمهای مختلف برای وظایف مختلف را کاهش میدهد و توسعه و پیادهسازی برنامههای داده را راحتتر میکند.
14. اسپارک در ابر (Cloud):
سازگاری آپاچی اسپارک با پلتفرمهای ابری مانند AWS، Azure و Google Cloud، باعث راحتتر شدن پیادهسازی و مقیاسپذیری شدهاست. کاربران اسپارک با بهرهگیری از مزایای خدمات ابری میتوانند از انعطافپذیری و صرفهجویی در هزینه منابع ابری برای رفع نیازهای پردازش دادههای کلان خود استفاده کنند.
15. بهینهسازی عملکرد:
بهبودها و بهینهسازیهای مداوم اسپارک به افزایش عملکرد کمک میکند. بهروزرسانیها در مدیریت حافظه، زمانبندی وظایف و مکانیزمهای جابجایی، با هدف افزایش سرعت و کارایی اسپارک طراحی شدهاند و اطمینان حاصل میکنند که این فریمورک با تقاضاهای روزافزون و جدید پردازش دادههای کلان همگام باشد.
پردازش بیگ دیتا با اسپارک

آپاچی اسپارک، قهرمان پردازش دادههای کلان است و توانسته روشهای ما را در مدیریت مجموعههای داده عظیم متحول کند. اما چه چیزی باعث میشود اسپارک به این شکل عمل کند؟ برای بهرهبرداری کامل از پردازش بیگ دیتا با آپاچی اسپارک، باید روشهای پردازش، اصول اساسی و مفاهیم کلیدی آن را درک کنید:
مجموعههای توزیعشده مقاوم (RDDs):
در قلب اسپارک، RDD (Resilient Distributed Dataset) قرار دارد که یک انتزاع داده بنیادی است. فرض کنید یک مجموعه بزرگ از دادهها دارید که به بخشهای کوچک تقسیم شده و در نودهای خوشه شما توزیع شدهاست. این همان RDD است! اما جادوی آن در انعطافپذیری و تابآوریاش نهفته است. اگر هر بخشی از دادهها گم شود، RDD بهطور خودکار آن را با استفاده از اطلاعاتی که درباره چگونگی ایجاد آن دارد، بازسازی میکند و دیگر نگران از دست رفتن دادهها و مختلشدن کارتان نخواهید بود!
تبدیلها (Transformation) و عملیات (Action):
تبدیلها را بهعنوان عملگرهایی تصور کنید که مجموعههای RDD را مانند بلوکهای ساختمانی دستکاری میکنند. شما میتوانید بدون اینکه دادههای اصلی را تغییر دهید این دادهها را فیلتر کنید، مپ کنید، پیوند دهید یا تحلیلهای پیچیده انجام دهید. از طرف دیگر، عملیاتها نتیجه نهایی را از یک یا چند RDD محاسبه کرده و به برنامه اصلی بازمیگردانند. برای درک بهتر عملیات، میتوانید آن را بهعنوان تحویل غذای نهایی پس از اتمام خرد کردن و پختوپز غذا تصور کنید!
گرافهای غیرمدور هدایتشده (DAGs):
زمانی که تبدیلها را زنجیرهای میکنید، اسپارک یک نقشهراه به نام DAG ایجاد میکند. این نقشه، تمام وابستگیها بین مجموعههای RDD را بهطور بهینه ترسیم کرده و اجرای کارآمد را تضمین میکند. درنتیجه، دیگر خبری از هزارتوی کدهای پیچیده نیست! DAG به اسپارک کمک میکند تا وظایف را در نودهای خوشه شما بهصورت موازی انجام دهد و تحلیل کد شما را به طرز چشمگیری تسریع بخشد.
مدیریت خوشه:
یادتان باشد که اسپارک بهتنهایی کار نمیکند. این فریمورک به یک مدیر خوشه مانند YARN یا Mesos وابسته است تا منابع را تخصیص داده و وظایف را در نودها زمانبندی کند. میتوانید این مدیر خوشه را بهعنوان یک رهبر ارکستر تصور کنید که کل سمفونی پردازش را هدایت میکند. این معماری توزیعشده به شما این امکان را میدهد که قدرت پردازش خود را بهراحتی با افزودن نودهای بیشتر به خوشه افزایش دهید.
مجموعهها و دیتافریمها:
با اینکه مجموعههای RDD پایه و اساس هستند، اسپارک انتزاعات سطح بالاتری مانند مجموعهها و دیتا فریمها را ارائه میدهد. این ویژگیها برای راحتتر کردن بهینهسازیهای داخلی و ادغام با دادههای ساختاری مانند جداول SQL بکار میروند. اگر مجموعهها و دیتا فریمها را مبلهای راحتی درنظر بگیریم، مجموعههای RDD نیز نیمکتهای معمولی و نهچندان راحت پارک هستند.
اکوسیستم اسپارک:
اسپارک تنها یک موتور نیست؛ بلکه یک اکوسیستم کامل است! در این اکوسیستم، کتابخانههایی مانند Spark SQL، MLlib و GraphX قابلیتهای خود را به کوئریهای SQL، یادگیری ماشین و پردازش گراف گسترش میدهند و شما با استفاده از آن میتوانید از پس هر چالشی برآیید.
مزایای آپاچی اسپارک
مهمترین مزایای استفاده از آپاچی اسپارک برای تیمهای توسعه عبارتنداز:
تسریع در توسعه اپلیکیشن
مدلهای برنامهنویسی استریمینگ و SQL آپاچی اسپارک که توسط کتابخانههای MLlib و GraphX پشتیبانی میشوند، به آسانتر کردن ساخت اپلیکیشنهایی که از یادگیری ماشین و تحلیل گراف بهره میبرند، کمک میکنند.
نوآوری سریعتر
انواع مختلف API، کار با دادههای نیمهساختاریافته و تبدیل دادهها را تسهیل کرده به تیمها این امکان را میدهند تا نوآوریهای خود را با سرعت بیشتری به پیش ببرند.
مدیریت آسان
یک موتور یکپارچه از کوئریهای SQL، دادههای استریم، یادگیری ماشین و پردازش گراف پشتیبانی میکند. تمام این ویژگیها، مدیریت دادهها را سادهتر میکنند.
بهینهسازی با فناوریهای باز
بنیاد OpenPOWER امکان تسریع GPU، CAPI Flash، RDMA، FPGA و نوآوری در یادگیری ماشین را فراهم میکند تا بدینصورت، عملکرد بارهای کاری آپاچی اسپارک را بهینه کند.
پردازش سریعتر
اسپارک بهدلیل داشتن موتور پیشرفته پردازش در حافظه و ذخیرهسازی دادهها در دیسک، میتواند تا ۱۰۰ برابر سریعتر از هادوپ عمل کند.
تسریع دسترسی به حافظه
اسپارک میتواند برای ایجاد یک فضای بزرگ حافظه برای پردازش دادهها استفاده شود. درنتیجه، کاربران میتوانند از طریق رابطها و با استفاده از پایتون، R و Spark SQL به دادهها دسترسی پیدا کنند.
«هدوپ» چیست؟
در دنیای پردازش دادهها، همیشه نام هدوپ در کنار آپاچی دیده میشود. اما آیا میدانید که هدوپ چیست و چه کاربردهایی دارد؟ هادوپ (Hadoop) مانند آپاچی استارک یک فریمورک متنباز است که از آن برای ذخیرهسازی و پردازش بیگ دیتا استفاده میشود. این فریمورک برای مدیریت حجمهای بسیار زیاد داده، از گیگابایت تا پتابایت، در محیطهای توزیعشده مناسب است. هادوپ شامل دو بخش اصلی است که عبارتنداز سیستم فایل توزیعشده هادوپ (HDFS) که برای ذخیرهسازی دادهها استفاده میشود و مدل پردازش MapReduce که برای پردازش دادهها بکار میرود.
کاربران با استفاده از هادوپ میتوانند با کمک خوشهای از سرورها، دادهها را بهطور موازی پردازش کنند و به این ترتیب زمان پردازش را بهطور قابلتوجهی کاهش دهند. از این فریمورک در صنایع مختلفی مانند سیستمهای مالی، بهداشت و درمان و تجارت الکترونیک استفاده میشود.
مقایسه Spark و Hadoop

Hadoop یک چارچوب متنباز است که سیستم فایل توزیعشده HDFS را بهعنوان فضای ذخیرهسازی، YARN را بهعنوان راهی برای مدیریت منابع محاسباتی مورد استفاده توسط برنامههای مختلف و پیادهسازی مدل برنامهنویسی MapReduce را بهعنوان موتور اجرا در خود دارد. در یک پیادهسازی معمولی Hadoop، موتورهای اجرایی مختلفی مانند Spark، Tez و Presto مستقر هستند.
در مقابل، آپاچی اسپارک یک چارچوب متنباز است که بر کوئری تعاملی، یادگیری ماشین و بارهای کاری بلادرنگ متمرکز شدهاست. این چارچوب، سیستم ذخیرهسازی مخصوص به خود را ندارد، اما تجزیهوتحلیلها را روی سایر سیستمهای ذخیرهسازی مانند HDFS یا سایر فروشگاههای محبوب مانند Amazon Redshift، Amazon S3، Couchbase، Cassandra و غیره اجرا میکند. اسپارک روی Hadoop از YARN برای به اشتراک گذاشتن یک خوشه و مجموعه داده مشترک مانند سایر موتورهای Hadoop استفاده میکند و سطوح ثابتی از خدمات و پاسخ را تضمین میکند.
با وجود تفاوتهای طراحی بین اسپارک و هادوپ، بسیاری از سازمانها از هر دو این چارچوبهای بیگ دیتا بهطور همزمان استفاده میکنند تا چالشهای تجاری خود را راحتتر و سریعتر رفع کنند.
محدودیتهای Apache Spark
آپاچی اسپارک مانند هر فناوری دیگری دارای محدودیتهایی است و کاربران در زمان انتخاب باید این محدودیتها را برای برنامههای بیگ دیتای خود بهدقت درنظر بگیرند. در ادامه، بهطور خلاصه به معرفی ۱۰ محدودیت اصلی آپاچی اسپارک میپردازیم:
1.نبود سیستم مدیریت فایل داخلی: اسپارک برای مدیریت فایلها به سیستمهای ذخیرهسازی خارجی مانند HDFS یا Amazon S3 وابسته است. این وابستگی میتواند پیچیدگی و بار اضافی را بههمراه داشتهباشد.
2.محدودیت در پردازش دادههای بلادرنگ: اسپارک بهجای پردازش دادهها بهصورت آنی و بلادرنگ، از میکرو-بچها استفاده میکند که میتواند منجر به تاخیر در پردازش دادههای استریم شود. این موضوع باعث میشود که از این ابزار برای کاربردهایی که نیاز به پردازش فوری دارند، کمتر استفاده کنیم.
3.مصرف و هزینه بالای حافظه: پردازش در حافظه به اسپارک سرعت میبخشد. با این حال، این پردازشها به منابع حافظه بالایی نیاز دارند و میتواند هزینههای عملیاتی را افزایش دهند. این مورد برای سازمانهایی که با دادههای بزرگ کار میکنند، چالشساز است.
4.مشکلات با فایلهای کوچک: در محیطهای بیگ دیتا، مدیریت تعداد زیادی فایل کوچک میتواند منجر به کاهش کارایی و افزایش زمان پردازش شود. این مشکل بهدلیل نیاز به مدیریت متادیتا برای هر فایل کوچک اتفاق میافتد.
5.تاخیر نسبی: اسپارک نسبت به سایر سیستمهای پردازش بیگ دیتا مانند Apache Flink، تاخیر بیشتری دارد. این تاخیر بهدلیل وابستگی اسپارک به میکرو-بچها است که میتواند در پردازش برنامههای حساس به زمان مشکلساز باشد.
6.محدودیت در انتخاب الگوریتمهای یادگیری ماشین: با اینکه کتابخانه MLlib اسپارک ابزارهای قدرتمندی برای یادگیری ماشین ارائه میدهد، اما در انتخاب الگوریتمها به اندازه کتابخانههای تخصصی مانند TensorFlow یا scikit-learn آزادی ندارید.
7.ناکارآمدی در پردازش تکراری: اسپارک در پردازش الگوریتمهای تکراری مانند خوشهبندی k-means یا PageRank کارایی نسبتا کمتری دارد؛ زیرا هر تکرار باید بهصورت جداگانه پردازش شود.
8.محدودیتهای پنجرهبندی در اسپارک استریمینگ: اسپارک استریمینگ از پنجرهبندی مبتنی بر زمان پشتیبانی میکند که به کاربران اجازه میدهد عملیاتهایی را بر روی دادهها در یک بازه زمانی مشخص انجام دهند. با این حال، این فریمورک بهطور پیشفرض از پنجرهگذاری مبتنی بر رکورد پشتیبانی نمیکند. این مسئله میتواند برای برنامههایی که نیاز به پردازش مبتنی بر رویداد یا کنترل دقیقتری بر دادهها دارند، محدودکننده باشد.
9.چالشهای مدیریت فشار برگشتی: اسپارک بهطور پیشفرض از مدیریت فشار برگشتی در بارهای کاری استریم پشتیبانی نمیکند. این مسئله میتواند در پردازش دادههای بزرگ چالشساز باشد.
10.نیاز به بهینهسازی دستی: بهینهسازی عملکرد اسپارک نیاز به تنظیمات دستی دارد و این فرایند میتواند زمانبر و مستعد خطا باشد. این موضوع در سیستمهای بزرگ و پیچیده باعث ایجاد بار اضافی میشود.
با وجود این محدودیتها، آپاچی اسپارک همچنان ابزاری ضروری و قدرتمند برای تحلیل دادههای کلان و پردازش دادههای استریم است و به شرطی که در زمینههای مناسب و با درنظر گرفتن چالشهای آن استفاده شود، میتواند مفید و راهگشا باشد.
آموزش نصب آپاچی اسپارک
در این بخش از آموزش اسپارک، به نحوه نصب آن میپردازیم. برای نصب آپاچی اسپارک، مراحل زیر را دنبال کنید:
مرحله ۱: دانلود و استخراج آپاچی اسپارک
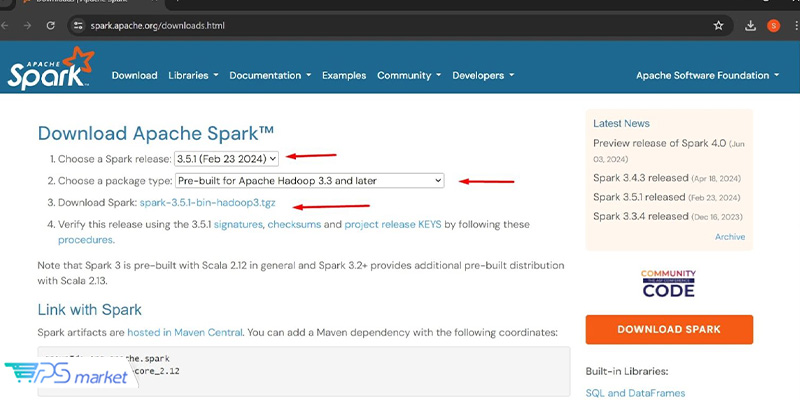
برای شروع، به صفحه دانلود آپاچی اسپارک بروید. در این صفحه باید نسخه اسپارک موردنظر خود را برای دانلود انتخاب کرده و نوع بسته را نیز انتخاب کنید. برای سازگاری با سیستمهای مدرن و تضمین بهینه بودن اسپارک برای محیطهای جدید hadoop، نسخه Pre-built for Apache Hadoop 3.3 و بالاتر را انتخاب کنید.
روی لینک دانلود پکیج کلیک کرده و فایل را در دستگاه محلی خود ذخیره کنید.
قبل از نصب آپاچی اسپارک، صحت پکیج دانلودشده را تایید کنید. برای تایید نسخهای که دانلود کردهاید، مراحل موجود در صفحه دانلود را دنبال کنید تا از ایمن بودن استفاده از آن مطمئن شوید.
پس از اتمام دانلود و تایید آن، پکیج را با استفاده از یک ابزار خط فرمان یا رابط گرافیکی استخراج کنید. برای استخراج خط فرمان، به پوشه دانلود بروید و دستور زیر را اجرا کنید و شماره نسخه خود را جایگزین کنید:
tar -xvzf spark--bin-hadoop3.tgz
این دستور، محتویات را در پوشهای به نام spark–bin-hadoop3 استخراج میکند.
مرحله ۲: پیکربندی متغیرهای محیطی
برای دسترسی به دستورات اسپارک از هر مکانی، پوشه Spark bin را به متغیر محیطی PATH سیستم خود اضافه کنید.
بهعنوان مثال، در یک سیستم مبتنی بر یونیکس، میتوانید خطوط زیر را به فایل .bashrc یا .zshrc خود اضافه کرده و آن را با نسخهای که دانلود کردهاید جایگزین کنید:
export SPARK_HOME=~/path/to/spark--bin-hadoop3 export PATH=SPARK_HOME/bin: PATH
پس از اضافه کردن این خطوط، دستور source ~/.bashrc یا source ~/.zshrc را برای اعمال تغییرات اجرا کنید.
مرحله 3: نصب PySpark
اگر قصد دارید از Spark با پایتون استفاده کنید، نصب PySpark را با دستور pip انجام دهید:
pip install pyspark
این دستور پکیج PySpark را نصب میکند و به شما امکان میدهد از قابلیتهای Spark در اسکریپتهای پایتون استفاده کنید.
مرحله 4: استفاده از Spark با Docker
Apache Spark همچنین ایمیجهای Docker را برای یک راهاندازی کانتینری ارائه میدهد. این ایمیجها در Dockerhub تحت حسابهای Apache Software Foundation و Official Images موجود هستند.
برای دریافت یک ایمیج Spark Docker، دستور زیر را اجرا کنید:
docker pull apache/spark
به خاطر داشته باشید که این ایمیجها ممکن است حاوی نرمافزار غیر ASF باشند. درنتیجه، باید فایلهای Docker را بررسی کرده تا از سازگاری آنها با الزامات استقرار خود مطمئن شوید.
مرحله ۵: پیوند دادن اسپارک با Maven
برای توسعهدهندگان جاوا و اسکالا، مصنوعات اسپارک در Maven Central میزبانی میشوند. برای افزودن اسپارک بهعنوان یک وابستگی، مختصات زیر را در فایل pom.xml خود وارد کنید:
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.5.1</version> </dependency>
این پیکربندی، پروژه شما را با اسپارک پیوند میدهد و به شما امکان میدهد تا برنامههای اسپارک را بهطور یکپارچه بسازید و اجرا کنید.
جمعبندی
در چشمانداز پویای فناوریهای پردازش دادهها، آپاچی اسپارک همچنان پابرجاست و در انقلاب بیگ دیتا، آینده تصمیمگیری مبتنی بر داده را شکل میدهد. برای کسبوکارها و سازمانهایی که با مجموعه دادههای بزرگ و تجزیهوتحلیلهای پیچیده دست و پنجه نرم میکنند، اسپارک یک راهحل عالی و چندمنظوره بهشمار میرود.
با اینکه اسپارک یک ابزار قدرتمند است، اما برای آشنایی با پتانسیلهای آن باید با سازوکار درونی آن بهخوبی آشنا باشید. به همین منظور، در این صفحه به تمام جوانب این ابزار پرکاربرد پرداختیم تا در زمان انتخاب، بینش کاملی از آن داشتهباشید.
سوالات متداول
آپاچی اسپارک چیست؟
آپاچی اسپارک یک فریمورک محاسباتی توزیعشده متنباز است که برای پردازش سریع و کارآمد دادههای کلان طراحی شدهاست. این فریمورک، قابلیتهای فوقالعادهای برای پردازش دستهای، پردازش استریم بلادرنگ، یادگیری ماشین و پردازش گراف دارد و به همین دلیل، در صنایع مختلفی مورداستفاده قرار میگیرد.
چگونه Apache Spark را راهاندازی کنیم؟
برای راهاندازی Apache Spark، ابتدا فایلهای اسپارک را از وبسایت رسمی دانلود کرده و آنها را در سیستم خود استخراج کنید. پس از آن، با استفاده از ترمینال، میتوانید اسپارک را با دستورات مناسب راهاندازی کرده و محیط اجرایی آن را پیکربندی کنید.
Hadoop چیست؟
هادوپ (Hadoop) یک فریمورک متنباز است که برای ذخیرهسازی و پردازش بیگ دیتا طراحی شدهاست. این فریمورک برای مدیریت حجمهای بسیار زیاد داده، از گیگابایت تا پتابایت، در محیطهای توزیعشده مناسب است و شامل دو بخش اصلی است: سیستم فایل توزیعشده هادوپ (HDFS) و مدل پردازش MapReduce.